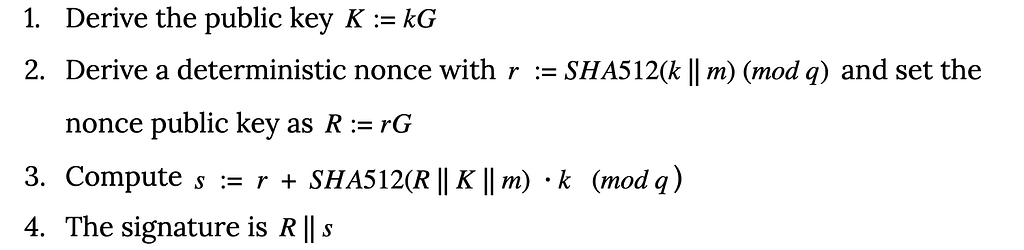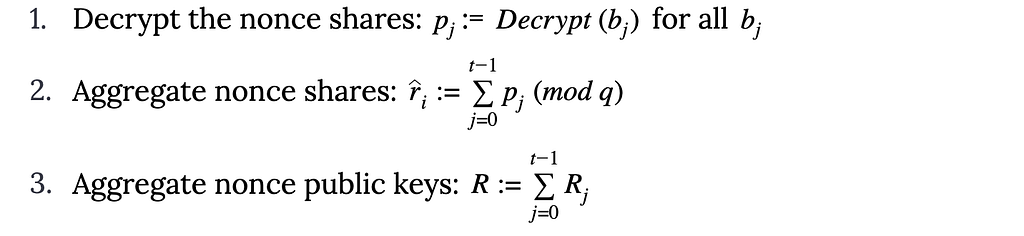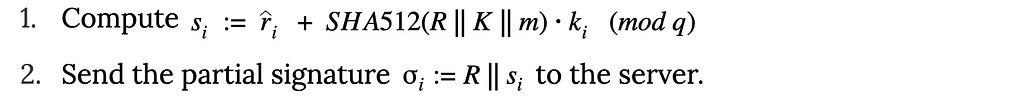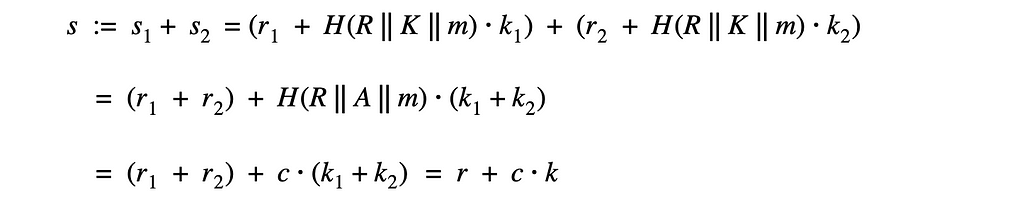Asset-oriented programming makes fundamental functions native to the programming language. DeFi needs more of that to improve security.
Decentralized finance (DeFi) is growing fast. Total value locked, a measure of money managed by DeFi protocols, has grown from $10 billion to a little more than $40 billion over the last two years after peaking at $180 billion.

The elephant in the room? More than $10 billion was lost to hacks and exploits in 2021 alone. Feeding that elephant: Today’s smart contract programming languages fail to provide adequate features to create and manage assets — also known as “tokens.” For DeFi to become mainstream, programming languages must provide asset-oriented features to make DeFi smart contract development more secure and intuitive.
Current DeFi programming languages have no concept of assets
Solutions that could help reduce DeFi’s perennial hacks include auditing code. To an extent, audits work. Of the 10 largest DeFi hacks in history (give or take), nine of the projects weren’t audited. But throwing more resources at the problem is like putting more engines in a car with square wheels: it can go a bit faster, but there is a fundamental problem at play.
The problem: Programming languages used for DeFi today, such as Solidity, have no concept of what an asset is. Assets such as tokens and nonfungible tokens (NFTs) exist only as a variable (numbers that can change) in a smart contract such as with Ethereum’s ERC-20. The protections and validations that define how the variable should behave, e.g., that it shouldn’t be spent twice, it shouldn’t be drained by an unauthorized user, that transfers should always balance and net to zero — all need to be implemented by the developer from scratch, for every single smart contract.
Related: Developers could have prevented crypto's 2022 hacks if they took basic security measures
As smart contracts get more complex, so too are the required protections and validations. People are human. Mistakes happen. Bugs happen. Money gets lost.
A case in point: Compound, one of the most blue-chip of DeFi protocols, was exploited to the tune of $80 million in September 2021. Why? The smart contract contained a “>” instead of a “>=.”
The knock-on effect
For smart contracts to interact with one another, such as a user swapping a token with a different one, messages are sent to each of the smart contracts to update their list of internal variables.
The result is a complex balancing act. Ensuring that all interactions with the smart contract are handled correctly falls entirely on the DeFi developer. Since there are no innate guardrails built into Solidity and the Ethereum Virtual Machine (EVM), DeFi developers must design and implement all the required protections and validations themselves.
Related: Developers need to stop crypto hackers or face regulation in 2023
So DeFi developers spend nearly all their time making sure their code is secure. And double-checking it — and triple checking it — to the extent that some developers report that they spend up to 90% of their time on validations and testing and only 10% of their time building features and functionality.
With the majority of developer time spent battling unsecure code, compounded with a shortage of developers, how has DeFi grown so quickly? Apparently, there is demand for self-sovereign, permissionless and automated forms of programmable money, despite the challenges and risks of providing it today. Now, imagine how much innovation could be unleashed if DeFi developers could focus their productivity on features and not failures. The kind of innovation that might allow a fledgling $46 billion industry to disrupt an industry as large as, well, the $468 trillion of global finance.

Innovation and safety
The key to DeFi being both innovative and safe stems from the same source: Give developers an easy way to create and interact with assets and make assets and their intuitive behavior a native feature. Any asset created should always behave predictably and in line with common sense financial principles.
In the asset-oriented programming paradigm, creating an asset is as easy as calling a native function. The platform knows what an asset is: .initial_supply_fungible(1000) creates a fungible token with a fixed supply of 1000 (beyond supply, many more token configuration options are available as well) while functions such as .take and .put take tokens from somewhere and put them elsewhere.
Instead of developers writing complex logic instructing smart contracts to update lists of variables with all the error-checking that entails, in asset-oriented programming, operations that anyone would intuitively expect as fundamental to DeFi are native functions of the language. Tokens can’t be lost or drained because asset-oriented programming guarantees they can’t.
This is how you get both innovation and safety in DeFi. And this is how you change the perception of the mainstream public from one where DeFi is the wild west to one where DeFi is where you have to put your savings, as otherwise, you’re losing out.
The author, who disclosed his identity to Cointelegraph, used a pseudonym for this article. This article is for general information purposes and is not intended to be and should not be taken as legal or investment advice. The views, thoughts, and opinions expressed here are the author’s alone and do not necessarily reflect or represent the views and opinions of Cointelegraph.